Summary
- csv 파일이나 excel 파일을 dataframe 형태로 불러오거나, 혹은 dataframe을 csv나 excel 파일 형태로 저장할 때 아래와 같은 코드를 사용할 수 있다.
- 엑셀 파일이 너무 커서 열리지 않을 때나 열어서 바로 분석하고 싶을 때 등등 아래 기능들을 활용할 수 있다.
- 함수별로 파라미터를 추가적으로 하나씩 더 붙여서 소개하였으나, 다양한 파라미터가 있으니 첨부된 링크를 확인해보자.
- 참고로 불러올 때는 함수 형태로 사용하지만 저장할 때는 메소드 형태로 사용한다.
즉, 불러올 때는 pandas.read_excel()과 같은 형태로 라이브러리에서 함수를 호출하는 형태이지만, 저장할 때는 생성된 데이터프레임을 저장하는 것이므로 (저장할 데이터프레임 변수 명).to_excel()과 같은 형태로 사용한다.
Contents
pandas는 데이터를 살펴보는 것부터 연산을 수행하는 것까지, 행렬 데이터를 다루기에 굉장히 편리한 라이브러리이다.
이 글에서는 pandas 라이브러리를 통해 csv파일과 excel파일을 불러오도록 한다.
1. 문법 소개
먼저 문법부터 소개하도록 한다.
전체 문법을 정리한 후 예시에서 엑셀 파일을 불러와 csv 파일을 저장하는 것까지 진행해본다.
1-1. 시작 전 pandas 라이브러리를 불러온다
import pandas as pd
1-2-1. 엑셀 파일을 dataframe 형태로 불러오기: read_excel()
* 기본형
pd.read_excel('파일 경로 & 파일명')
* 엑셀 파일의 특정 시트만 불러오는 경우
pd.read_excel('파일 경로 & 파일명', sheet_name='시트명')
엑셀 파일을 불러올 때에는 가장 많이 사용한 파라미터가 sheet_name이기에 sheet_name을 함께 언급하였으나, 더 많은 파라미터가 있으니 필요하다면 아래 공식 Document를 통해 확인해보도록 한다.
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
pandas.read_excel — pandas 2.0.1 documentation
Additional strings to recognize as NA/NaN. If dict passed, specific per-column NA values. By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IN
pandas.pydata.org
1-2-2. dataframe을 excel로 저장하기: to_excel()
* 기본형
(데이터프레임 변수명).to_excel('파일 경로 & 파일명')
* 엑셀 파일의 시트 이름을 지정하는 경우
(데이터프레임 변수명).to_excel('파일 경로 & 파일명', sheet_name='시트명')
이 또한 다양한 파라미터들이 있으니 필요하다면 아래 공식 Document를 통해 확인해보자.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_excel.html
pandas.DataFrame.to_excel — pandas 2.0.1 documentation
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and
pandas.pydata.org
1-3-1. csv 파일을 dataframe 형태로 불러오기: pd.read_csv()
* 기본형
pd.read_csv('파일 경로 & 파일명')
* encoding을 변경할 경우 (default='utf-8')
pd.read_csv('파일 경로 & 파일명', encoding='cp949')
csv를 불러올 경우 많이 사용하는 파라미터인 encoding을 예시로 들어보았다. 추가적인 파라미터를 살펴보려면 아래 링크를 확인해보자.
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
pandas.read_csv — pandas 2.0.1 documentation
Delimiter to use. If sep is None, the C engine cannot automatically detect the separator, but the Python parsing engine can, meaning the latter will be used and automatically detect the separator by Python’s builtin sniffer tool, csv.Sniffer. In addition
pandas.pydata.org
1-3-2. dataframe을 csv 파일로 저장하기: to_csv()
* 기본형
(데이터프레임 변수명).to_csv('파일 경로 & 파일명')
* encoding을 변경할 경우 (마찬가지로 default='utf-8')
(데이터프레임 변수명).to_excel('파일 경로 & 파일명', encoding='cp949')
csv는 텍스트 형태이다보니 구분자 등 더 다양한 파라미터를 활용할 수 있을 것으로 보인다. to_csv의 파라미터들을 더 살펴본다면 아래 링크를 확인해보자.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_csv.html
pandas.DataFrame.to_csv — pandas 2.0.1 documentation
String, path object (implementing os.PathLike[str]), or file-like object implementing a write() function. If None, the result is returned as a string. If a non-binary file object is passed, it should be opened with newline=’’, disabling universal newli
pandas.pydata.org
2. 예제
2-1. csv 파일 불러오기
나는 BBC text classification을 수행하기 위해 bbc-text.csv 파일을 받았다.
데이터가 필요한 경우에는 이 링크(https://storage.googleapis.com/dataset-uploader/bbc/bbc-text.csv)를 클릭하자.
위 파일을 코드를 통해 불러와보자.
* 코드
import pandas as pd
dataset = pd.read_csv('./Dataset/bbc-text.csv')
dataset.sample(5)
* 실행 화면
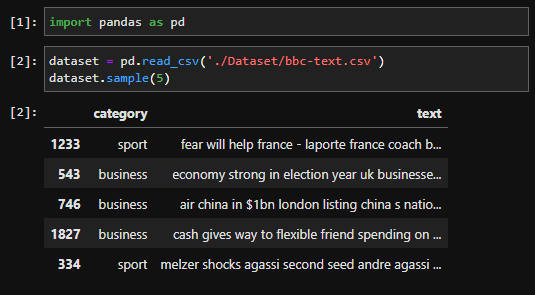
read_csv() 함수를 통해 bbc-text.csv 파일을 dataframe 형태로 받은 후 dataset 변수에 저장하였다.
또한 sample(5) 메소드를 통해 임의의 5개를 함께 살펴보았다.
2-2. text 길이를 담은 행 추가하기
이 기능은 불러오고 저장을 하는 데에 필수적이지는 않으나, 똑같이 저장하면 재미없으니 한 번 추가해보았다.
* 코드
dataset['text_length'] = [len(text) for text in dataset['text']]
dataset.sample(5)
* 실행 화면
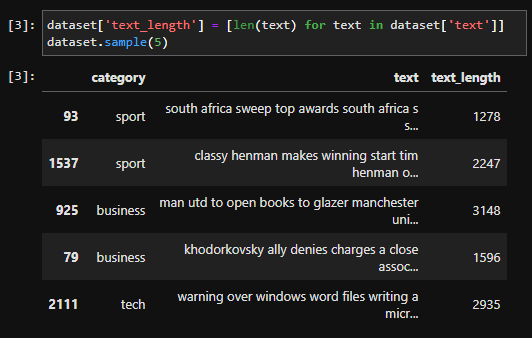
길이 열(text_length)이 추가된 것을 살펴볼 수 있다.
위 코드가 궁금한 사람들을 위해 간단하게 설명해주자면 리스트 컴프리헨션 문법을 통해 길이 값이 담긴 리스트를 구하고, 데이터 프레임 열을 생성하여 생성한 리스트 값을 넣어주었다.
참고로 sample() 메소드는 임의의 행을 보여주는것으로 실행할 때마다 값이 달라진다.
2-3. excel로 저장하기
* 코드
dataset.to_excel('bbc-example.xlsx', sheet_name='added_length')
* 실행 결과



데이터 프레임에 to_excel 파라미터를 통해 저장하면 코드 실행 완료 후 잠시 지난 뒤 파일이 생성되는 것을 확인할 수 있다.
저장된 파일을 열어 살펴보면 내가 지정한 파일명과 시트명으로 저장된 것을 살펴볼 수 있고, 추가한 길이 열이 있는 것도 함께 확인할 수 있다.
Conclusion
- summary에서도 언급하였으나 여기에 기록되지 않은 파라미터들이 많으니, 불러올 때 추가적인 기능이 필요하다면 첨부된 링크를 자세히 확인해보자.
References
[1] 참고한 글은 pandas 공식 document로, 각 구역에 링크를 게재해두었음.
그럼 진짜 끝! 안녕~!
